There is a Better Way to Access and Move Your Data
You thought you were paying for a solution to your problems. Instead, you got antiquated systems, endless maintenance and consumption pricing.
You need to be ahead of your AI initiatives. It’s time for a change.
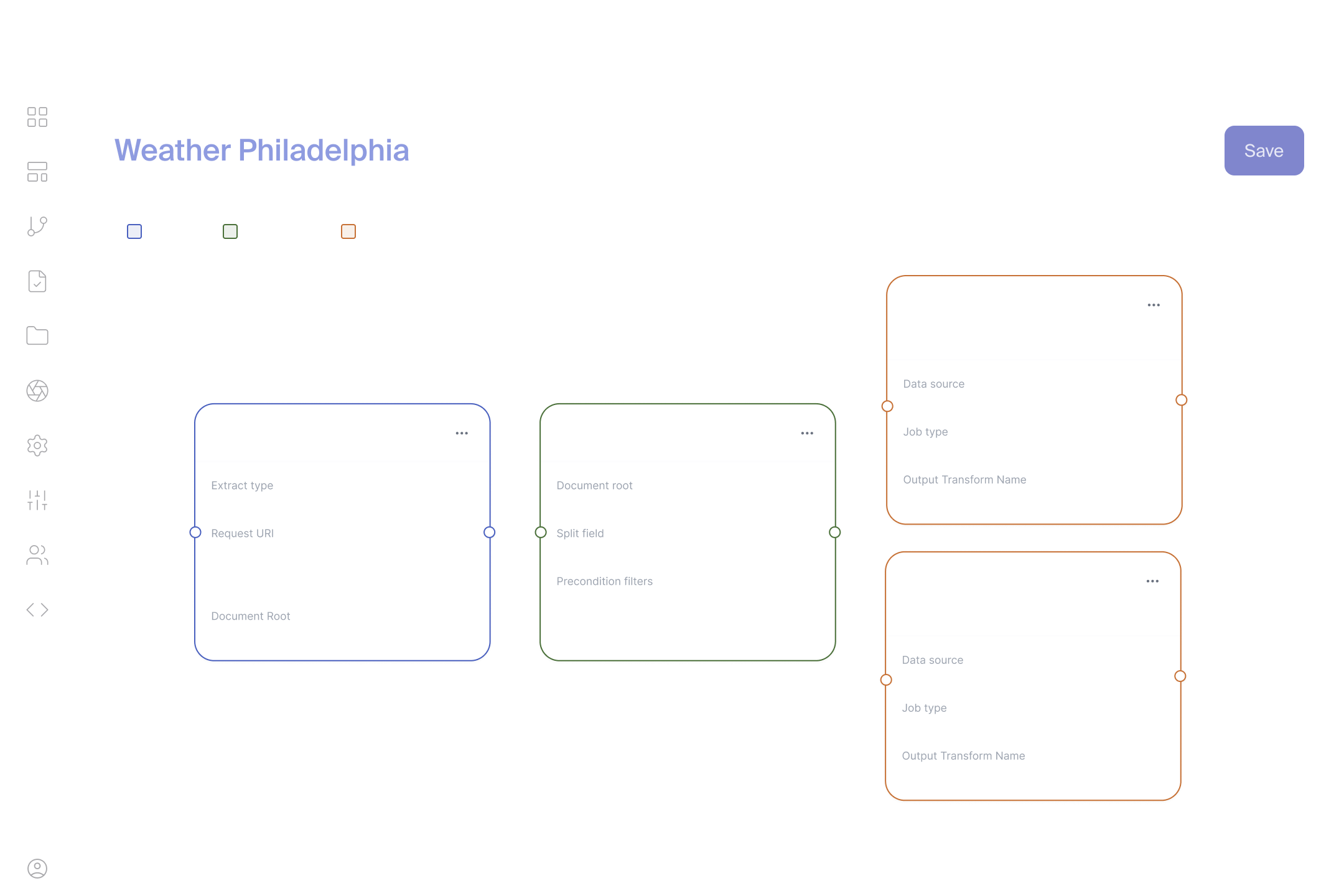
EASL replaces that broken promise with defined workflows and predictable pricing.
Here’s what control looks like.
Structured, observable data movement—defined by workflows, not stitched together by connectors.
“Our collaboration with EASL has been foundational to delivering on Jobologi’s vision for real-time, data-driven performance insights in the hospitality industry. While Jobologi focuses on translating operational data into strategic intelligence for our clients, EASL ensures the underlying data architecture is secure, scalable, and seamlessly integrated. We’ve transformed fragmented system data into a unified infrastructure that powers dashboards and actionable decision-making for country club leadership. EASL is not just a vendor, they are a critical technology partner that cultivates growth.”

The problem isn’t your data. It’s that you don’t trust what happens to it.
Your data stack fails in ways you don't see coming. A pipeline breaks and nobody notices for three days. You want to make a simple change, but it'll take two weeks and might break something else. Every fix is a workaround that very few people on your team understand.
In many organizations, pipelines become personal territory. Teams defend what they built and knowledge stays local. When control lives with individuals instead of structure, the business carries the risk.
Talk to EASL about your environmentOver time, your team stops trusting the system and starts working around it.
You don't trust your data outputs
Errors hide in your pipelines for days before anyone notices.
You don't trust your workflows
Which processes are running? Which are broken? Nobody really knows.
You don't trust the cost model
Surprise fees. Vendor lock-in. Custom requests that explode your budget.
You don't trust that change won't break everything
New data source? API update? Hope nothing breaks downstream.
Most platforms connect, but don’t offer control.
You need both for AI.
Traditional ETL approaches focus on moving data from point A to point B. As your environment expands, those connections multiply. Custom logic accumulates while short-term solutions remain long after the deadline passes.
The result is an environment that technically works, but becomes expensive to maintain and difficult to evolve.
A workflow-driven approach changes how data moves
Instead of layering more integrations into an already crowded stack, EASL centers everything around defined workflows.
A workflow makes data movement explicit: where it starts, how it is validated, how it changes and what it costs to operate. That structure exists before anything goes into production.
Rather than adding yet another generic connector, you’re establishing control over how data moves across the organization.
Defined workflows instead of point-to-point integrations
Predictable pricing tied to workflows
Clear visibility into what is running and why
Designed to adapt as requirements change
Configure. Monitor. Scale. Without the drama.
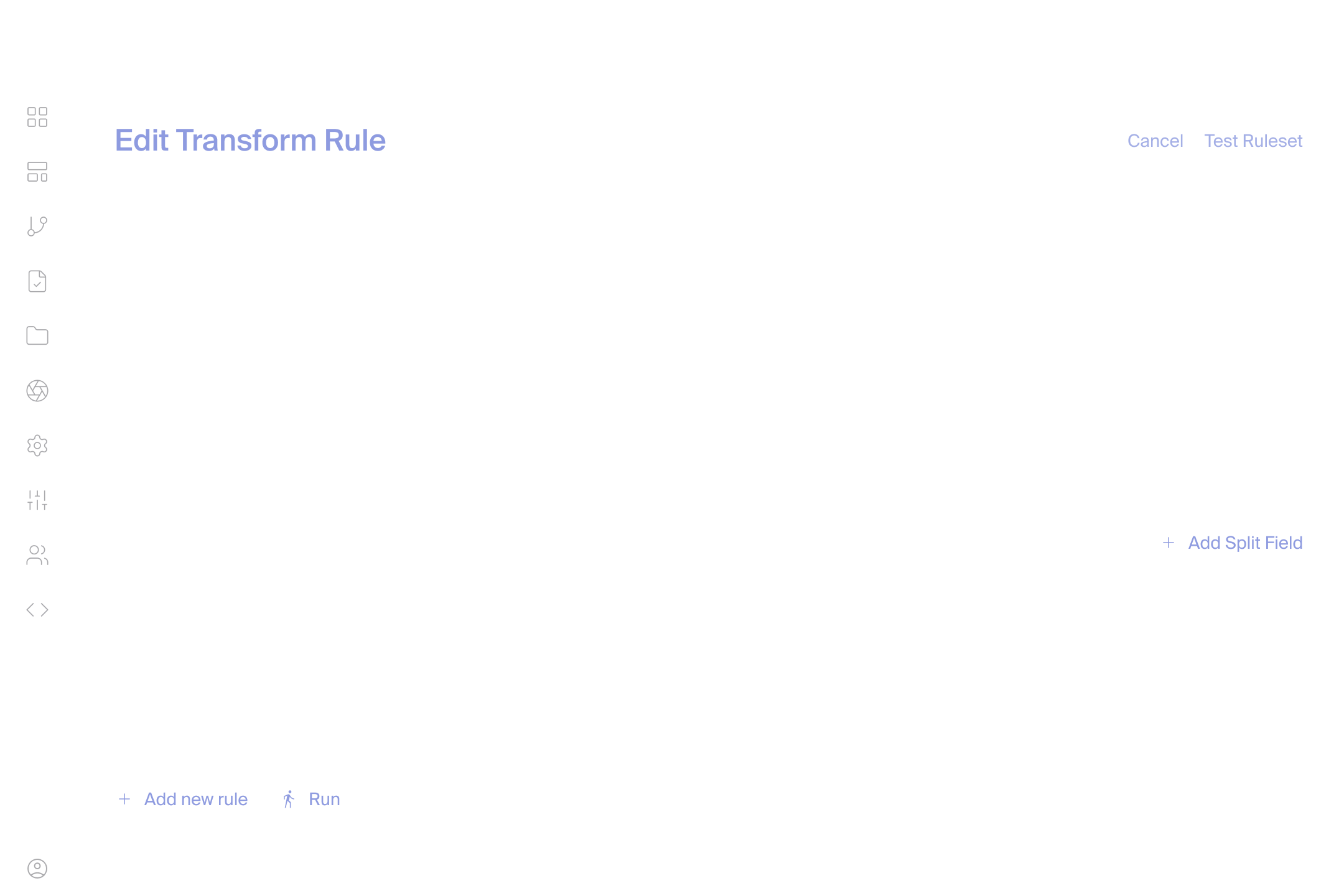
Configure in Hours, Not Months
New data source? 48 hours to launch. Need to change a mapping rule or adjust a schedule? 10 minutes. You don’t have to file a ticket or fund a new project just to make progress. You configure what you need and keep going.
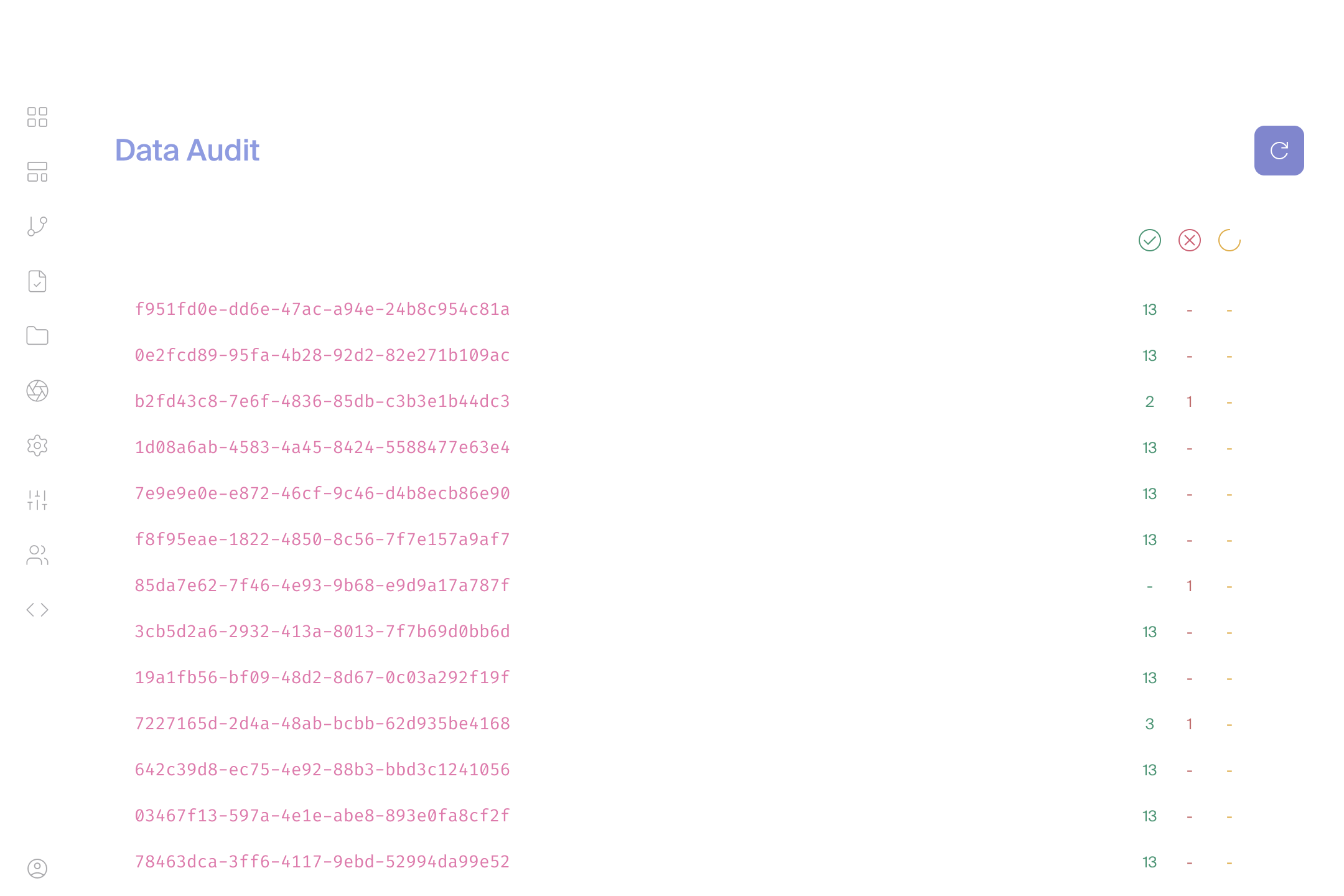
See Everything, Fix Anything Fast
Real-time monitoring shows you exactly what's happening with your data. When errors pop up (and they will), you'll know in minutes, not days. Average error resolution: 9 minutes.
Built to Handle What You Throw At It
256-bit encryption. Zero data loss. Deploy in your cloud, on-prem, or behind a client firewall. Process 25,000+ daily jobs without breaking a sweat.
Results you can measure
For teams where data movement affects revenue, risk or reputation.
Your AI initiatives expect more.
EASL is built for teams where data runs real parts of the business—operations, reporting, compliance, customer systems. In that kind of environment, you can’t afford guesswork around cost or reliability.





The EASL Difference
A better way to move data and create value.





import { sap_client } from "@lib/sap";
const config = {
host: "erp.acme.corp",
tenant: "prod_01",
modules: ["FI", "CO", "SD"],
mapping: "sap_resource_to_internal_schema",
cache: true,
logging: "verbose"
};
export const sap_sync = () => sap_client.init(config);-- Snowflake Integration Script
-- Purpose: Warehouse Sync
CREATE OR REPLACE STAGE incoming_data;
COPY INTO analytics_raw
FROM @incoming_data
FILE_FORMAT = (TYPE = 'JSON')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
PURGE = TRUE;
-- End of Warehouse Script#!/usr/bin/perl
# Legacy Homegrown Data Pipeline
use strict;
use DBI;
my $dbh = DBI->connect("DBI:mysql:legacy_db", "admin");
my $sth = $dbh->prepare("SELECT * FROM v1_leads");
$sth->execute();
my $mapping = "legacy_sql_to_modern_schema_v4";
while (my $row = $sth->fetchrow_hashref()) {
push @data, transform_row($row);
}import Stripe from "stripe";
const stripe = new Stripe(process.env.KEY);
const process_webhook = async (event) => {
const data = event.data.object;
const metadata = data.metadata;
const mapping = "stripe_subscription_to_user_plan";
return await update_billing_state(data.id);
};{
"source": "unstructured_node",
"parser": "ai_inference_engine",
"confidence": 0.98,
"extraction_rules": {
"strategy": "pattern_match",
"fallback": "manual_review",
"mapping": "raw_json_to_structured_object",
"validation": "strict",
"schema": "v1.4.2"
}
}EASL Workflow-Driven Data Orchestration
Transform in Motion
Enrich with Context
Apply a Governing Ontology
Track Lineage Automatically
Validate Continuously
Audit Every Record
What a better way looks like
How companies are using EASL today.



Let’s talk about your data challenges
We're real people who actually want to hear what's not working. Fill out the form and we'll get back to you within an hour. Or call us at +1 (844) 432-7583 if you'd rather just talk it through.